Design and Spatial Analysis of On-Farm Strip Trials
From Principles to Simulation Evaluations
02/12/2025
Fundamental attributes of an experiment
Replication
Blocks
Randomisation
 (https://www.livingfarm.com.au)
(https://www.livingfarm.com.au)
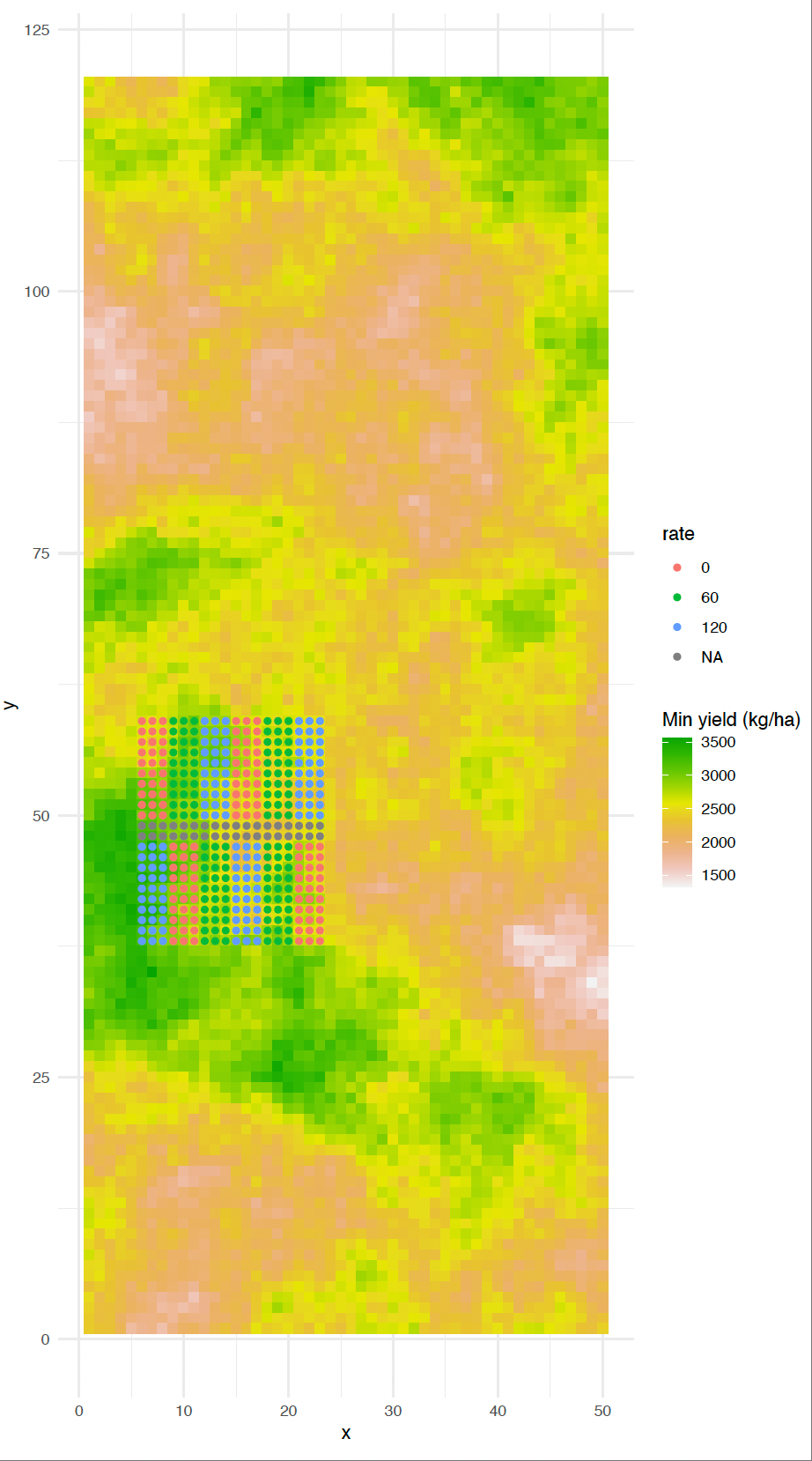
Illustration of OFE trial designs

Illustration of some OFE trial designs, including strip-based, grid-based, Latin square, and gradient layouts. These designs support different analytical goals, such as treatment comparison, spatial modelling, and rate-response analysis (Li, Mieno, and Bullock (2023))
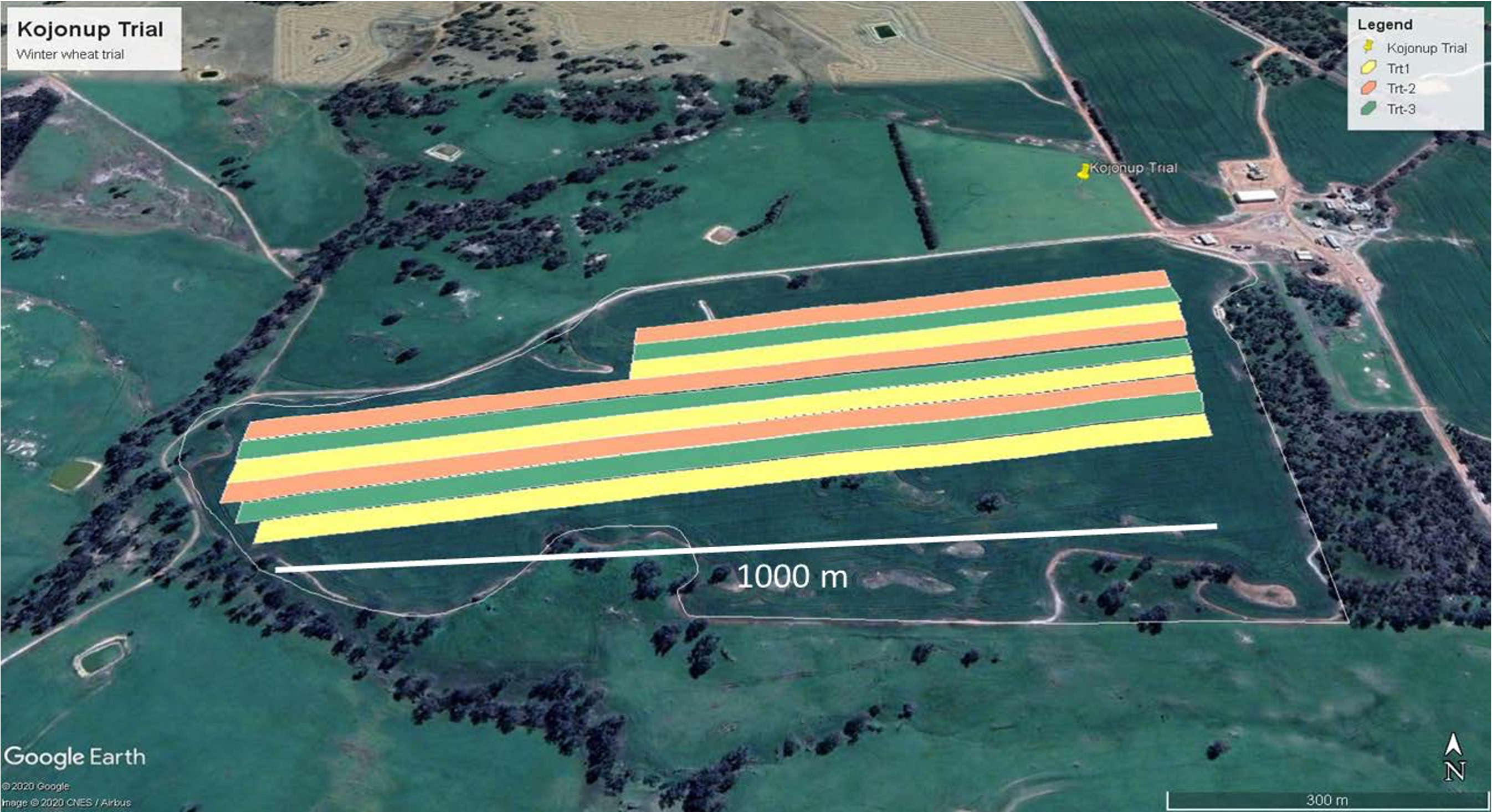
A typical long strip trial
Strip dimensions:
Width: 10-30m (machinery width dependent)
Length: 200m-1km (field size dependent)
Area: 0.2-1.5 ha per strip
Number: 2-6 treatments typical
Do these principles still hold for OFE


Previous studies on OFE design
For continuous responses, Prior research (Cao et al. 2022, 2024; Rakshit et al. 2020; Piepho et al. 2011; Pringle, Cook, and McBratney 2004) conclusively showed systematic designs outperform randomised designs for spatial analysis of continuous variables
Linear mixed model for OFE
Core concept: Linear Mixed Models treat large strip OFEs similar to Multi-Environment Trials (MET), where pseudo-environments (PE) represent different zones within the field (Stefanova et al. (2023)).

Linear mixed model for OFE
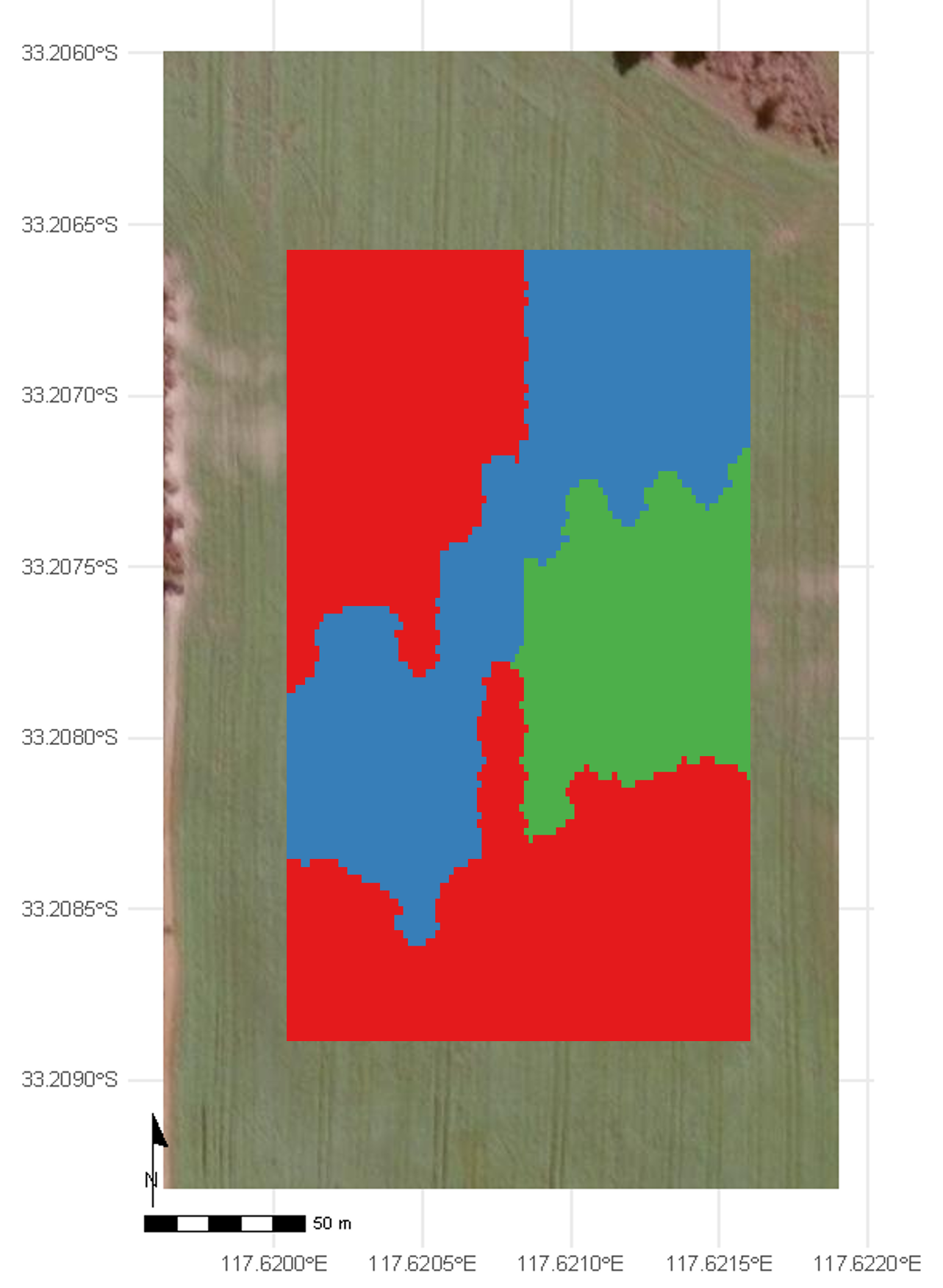
Stacked replicated design
This design is especially useful when:
Field length is limited, but replication is still required.
High-resolution spatial data is available, allowing for detailed modelling.

Simulation study - LMM
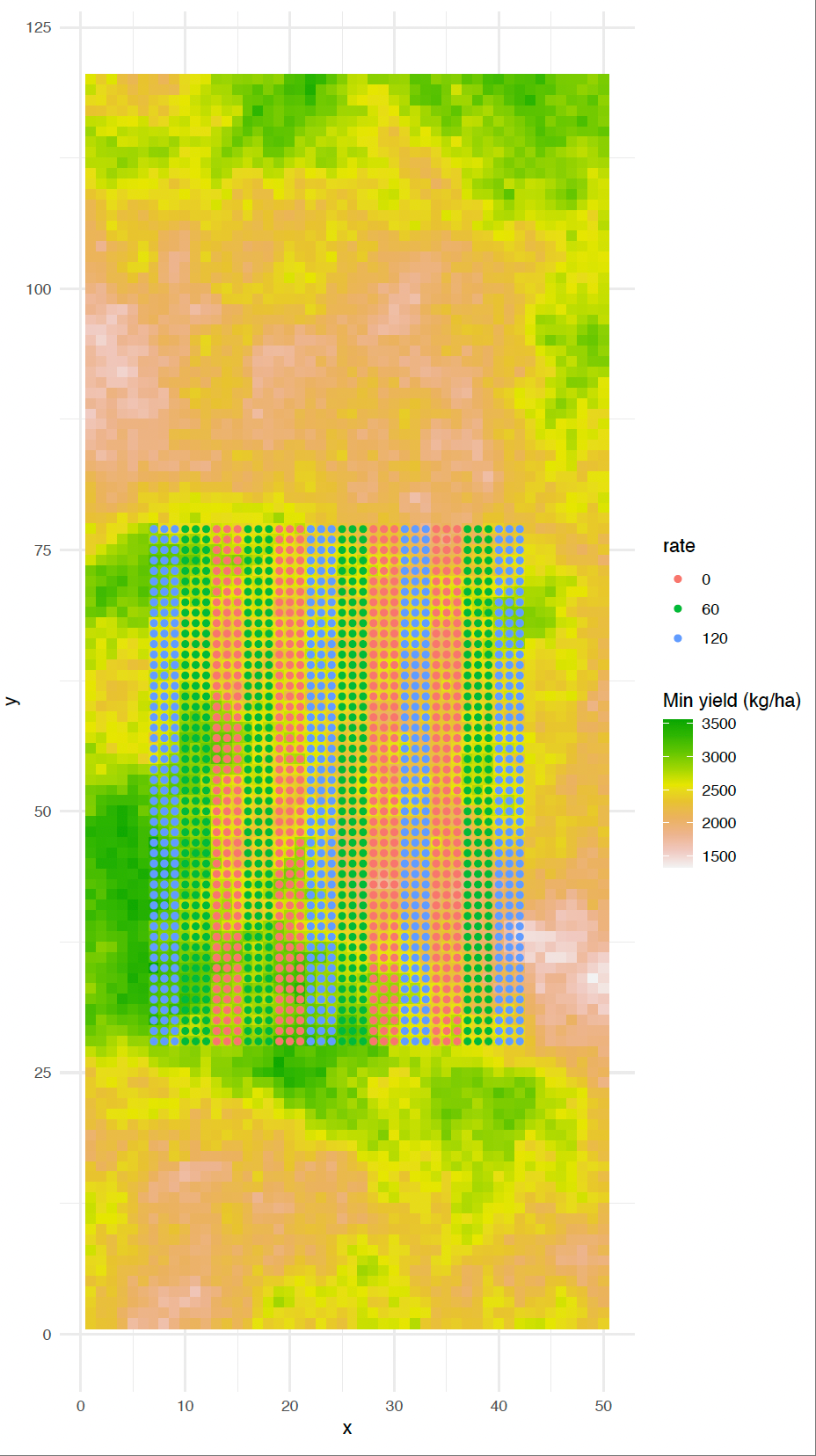

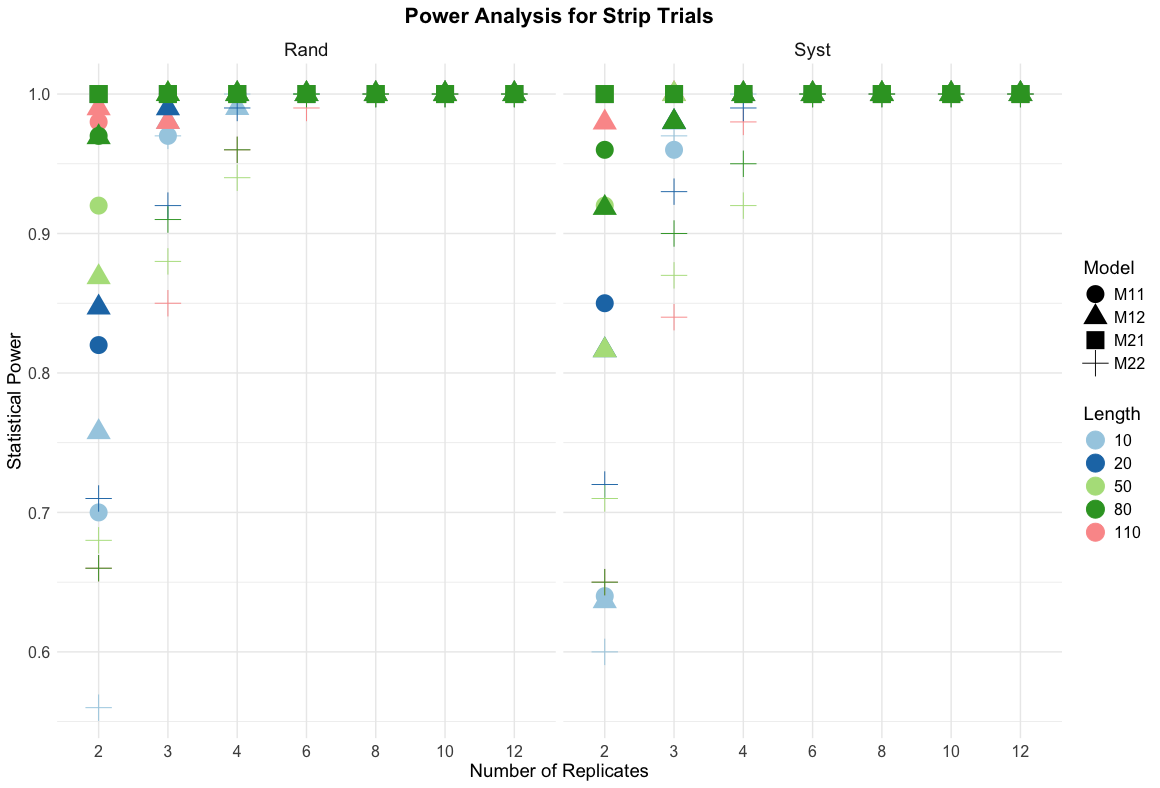
Result for strip trials

Boxplots of relative absolute difference (RAD) across different trial lengths, models, and designs of coefficients of strip trials. Each panel represents a combination of trial length and model (M11–M22), with RAD values compared between randomised and systematic strip designs. Lower RAD values indicate more accurate treatment effect estimation. Randomised designs and models incorporating spatial terms (M12,M22) show improved performance.
Statistical powers of strip trials

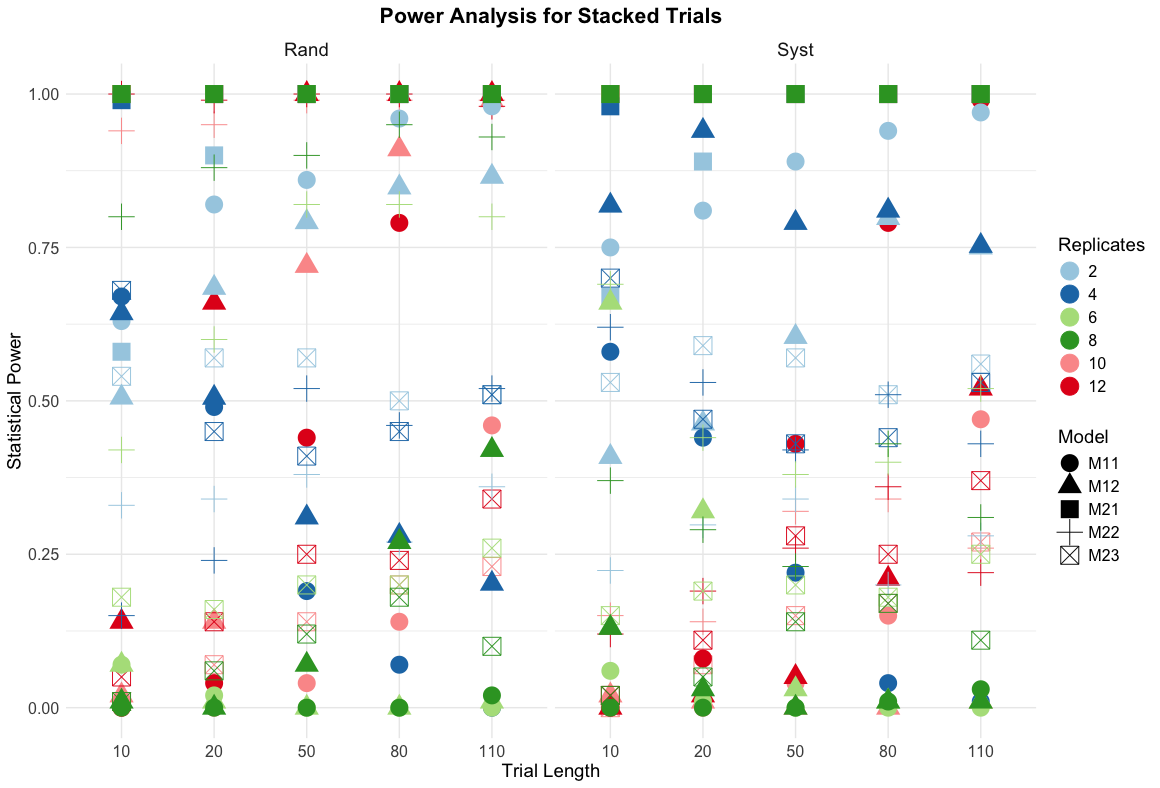
Result for stacked trials

Boxplots of relative absolute difference (RAD) for stacked replicate trials across different trial lengths and models. Each panel represents a combination of trial length and model (M11–M23), with RAD values compared between randomised and systematic designs. While randomised designs generally show slightly lower RAD values, the differences are less pronounced than in strip trials.
Statistical powers of stacked trials
Acknowledgements
Special thanks to EECMS, CBADA, C4AP & CCDM Curtin University
